API поиска и внутреннее устройство
Диаграмма компонентов поиска
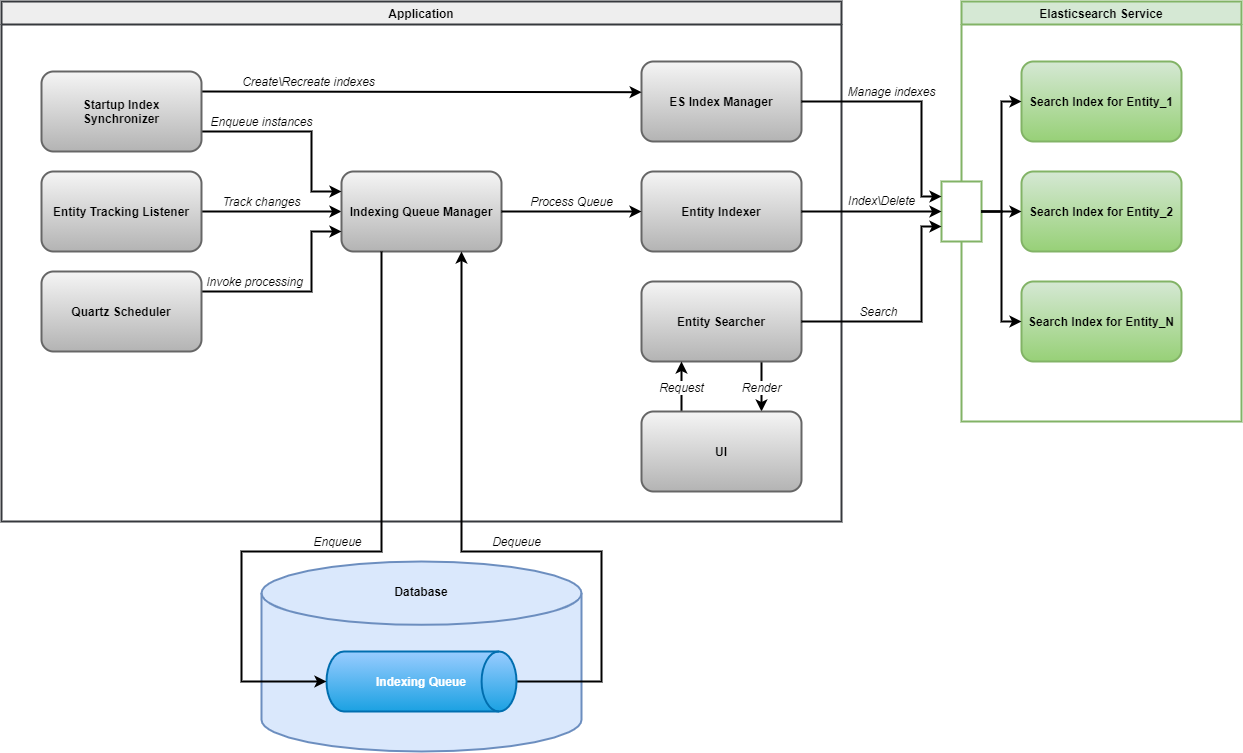
Дополнение Search включает следующие компоненты:
-
Startup Index Synchronizer - автоматически проверяет и пересоздает нерелевантные или отсутствующие индексы при запуске приложения. Запускает фоновый процесс с постановкой в очередь всех экземпляров сущностей, связанных с созданными индексами.
-
Entity Tracking Listener - отслеживает изменения индексированных сущностей и ставит в очередь соответствующие элементы очереди.
-
Quartz Scheduler - планирует задачу, которая периодически обрабатывает элементы очереди индексации.
-
Indexing Queue Manager - ставит элементы в очередь индексации. Обрабатывает ранее поставленные в очередь элементы и выполняет соответствующие действия через Entity Indexer.
-
Entity Indexer - выполняет операции с данными индекса: сохраняет и удаляет экземпляры сущностей.
-
Index Manager - управляет метаданными индекса: создает и удаляет индексы, проверяет маппинги.
-
Entity Searcher - выполняет поиск по индексам и возвращает результат поиска, который может быть отображен на экране.
API индексации
Если вы хотите индексировать/удалять экземпляры сущностей напрямую, без постановки события в очередь, используйте методы EntityIndexer:
-
index(Object entityInstance)- сохраняет предоставленный экземпляр сущности в индекс. -
indexCollection(Collection<Object> entityInstances)- сохраняет предоставленные экземпляры сущностей в индекс. -
indexByEntityId(Id entityId)- сохраняет экземпляр сущности в индекс по предоставленномуid. -
indexCollectionByEntityIds(Collection<Id> entityIds)- сохраняет экземпляры сущностей в индекс по предоставленнымid. -
delete(Object entityInstance)- удаляет предоставленный экземпляр сущности из индекса. -
deleteCollection(Collection<Object> entityInstances)- удаляет предоставленные экземпляры сущностей из индекса. -
deleteByEntityId(Id entityId)- удаляет экземпляр сущности из индекса по предоставленномуid. -
deleteCollectionByEntityIds(Collection<Id> entityIds)- удаляет экземпляры сущностей из индекса по предоставленнымid.
Если вы хотите ставить экземпляры в очередь для индексации/удаления, используйте методы IndexingQueueManager:
-
emptyQueue()- удаляет все элементы из очереди индексации. -
emptyQueue(String entityName)- удаляет все элементы, связанные с предоставленной сущностью, из очереди индексации. -
enqueueIndex(Object entityInstance)- ставит в очередь событие индексации для предоставленного экземпляра сущности. -
enqueueIndexCollection(Collection<Object> entityInstances)- ставит в очередь события индексации для предоставленных экземпляров сущностей. -
enqueueIndexByEntityId(Id entityId)- ставит в очередь событие индексации для предоставленногоidсущности. -
enqueueIndexCollectionByEntityIds(Collection<Id> entityIds)- ставит в очередь события индексации для предоставленныхidсущностей. -
enqueueIndexAll()- ставит в очередь события индексации для всех экземпляров всех сущностей, настроенных для индексации. -
enqueueIndexAll(String entityName)- ставит в очередь события индексации для всех экземпляров предоставленной сущности. Эта сущность должна быть предварительно настроена для индексации. -
enqueueDelete(Object entityInstance)- ставит в очередь событие удаления для предоставленного экземпляра сущности. -
enqueueDeleteCollection(Collection<Object> entityInstances)- ставит в очередь события удаления для предоставленных экземпляров сущностей. -
enqueueDeleteByEntityId(Id entityId)- ставит в очередь событие удаления для предоставленногоidсущности. -
enqueueDeleteCollectionByEntityIds(Collection<Id> entityIds)- ставит в очередь события удаления для предоставленныхidсущностей. -
processNextBatch()- извлекает следующую партию элементов из очереди индексации и обрабатывает их. -
processNextBatch(int batchSize)- извлекает следующую партию (размеромbatchSize) элементов из очереди индексации и обрабатывает их. -
processEntireQueue()- извлекает все элементы из очереди индексации и обрабатывает их.
API поиска
Если вы хотите выполнять поиск сущностей в индексе, используйте методы EntitySearcher:
-
SearchResult search(SearchContext searchContext, String searchStrategy)- выполняет поиск по поисковым индексам в соответствии с предоставленнымSearchContextи именем стратегии поиска. -
search(SearchContext searchContext)- аналогичен предыдущему, но использует стратегию поиска по умолчанию (SearchStrategy). -
searchNextPage(SearchResult previousSearchResult)- выполняет поиск следующей страницы на основеSearchResultпредыдущего поискового запроса. Возвращает собственныйSearchResult, который может быть использован для следующего вызова.
Возвращаемый объект SearchResult содержит данные результата:
-
SearchContext- описывает основные настройки текущего поиска:-
searchText- текст для поиска. -
size- максимальное количество возвращаемых документов. -
offset- количество документов, которые должны быть пропущены. -
entities- коллекция имен сущностей для поиска. Если не указана, поиск будет выполнен по всем индексированным сущностям.
-
-
SearchStrategy- описывает способ обработкиsearchText.
Также вы можете использовать SearchResult для загрузки коллекции связанных экземпляров сущностей. Для этой цели используйте методы SearchResultProcessor:
-
Collection<Object> loadEntityInstances(SearchResult searchResult) -
Collection<Object> loadEntityInstances(SearchResult searchResult, Map<String, FetchPlan> fetchPlans)
EntityIndexing MBean
Дополнение Search предоставляет MBean с именем объекта jmix.search:type=EntityIndexing, который имеет следующие операции:
-
emptyIndexingQueue- удаляет все элементы из очереди индексации. Доступны два варианта этой операции:-
с параметром
entityName- удаляет только все экземпляры этой сущности. -
без параметров - удаляет экземпляры всех сущностей.
-
-
enqueueIndexAll- ставит в очередь все экземпляры индексированных сущностей. Доступны два варианта этой операции:-
с параметром
entityName- ставит в очередь экземпляры только этой сущности. -
без параметров - ставит в очередь все экземпляры всех индексированных сущностей.
-
-
processEntireIndexingQueue- обрабатывает все элементы в очереди индексации. -
processIndexingQueueNextBatch- обрабатывает следующую партию элементов в очереди индексации. -
recreateIndex- удаляет и создает индекс, связанный с предоставленной сущностью. Все данные будут потеряны. -
recreateIndexes- удаляет и создает все поисковые индексы, определенные в приложении. Все данные будут потеряны. -
synchronizeIndexSchema- синхронизирует схему индекса, связанного с предоставленной сущностью. Это может привести к удалению этого индекса со всеми данными - зависит от стратегии управления схемой. -
synchronizeIndexSchemas- синхронизирует схемы всех поисковых индексов, определенных в приложении. Это может привести к удалению индексов со всеми их данными - зависит от стратегии управления схемой. -
validateIndex- проверяет схему поискового индекса, связанного с предоставленной сущностью, и отображает статус. -
validateIndexes- проверяет схемы всех поисковых индексов, определенных в приложении, и отображает статус для всех индексов.
Контроль доступа и пагинация
Контроль доступа к данным выполняется дополнением Search в два этапа:
-
Предварительный поиск - проверяет политики сущностей и исключает индексы, связанные с запрещенными сущностями. Политики атрибутов также применяются: только атрибуты сущности, которые текущий пользователь может прочитать, включаются в запрос поиска, поэтому совпадения в ограниченных атрибутах не возвращаются. Если текущий пользователь не имеет доступа к какой-либо из запрашиваемых сущностей, поиск возвращает пустой результат.
-
Пост-поиск - проверяет, есть ли политики на уровне строк, настроенные для найденных сущностей. Если они существуют, найденные экземпляры перезагружаются для применения политик безопасности.
EntitySearcher пытается заполнить всю страницу данными во время выполнения своего поискового запроса. Если некоторые данные исключены из текущего набора результатов из-за ограничений безопасности, и в индексах есть больше подходящих документов, EntitySearcher автоматически выполняет дополнительные поисковые запросы со смещенным offset’ом, чтобы получить больше данных. Это может происходить многократно, пока страница не будет заполнена или пока не закончатся результаты.