Артефакты Процесса
В течение жизненного цикла процесса создаются различные артефакты.
На диаграмме ниже вы можете увидеть, как эти артефакты связаны. Сначала пользователь создает модель процесса, представленную XML-файлом. Обычно один XML-файл содержит одну модель. Однако в случае модели сотрудничества, файл может включать несколько моделей.
Далее, модель разворачивается на сервере. Это происходит в два этапа:
-
Создание объекта развертывания.
-
Создание определения процесса для каждой модели включенной в развертывания.
Чтобы инициировать процесс, сервер генерирует экземпляр процесса. Во время выполнения, для конкретных потоков процесса могут создаваться execution объекты.
Наконец, экземпляр процесса может быть преобразован в исторический экземпляр процесса или удалён.
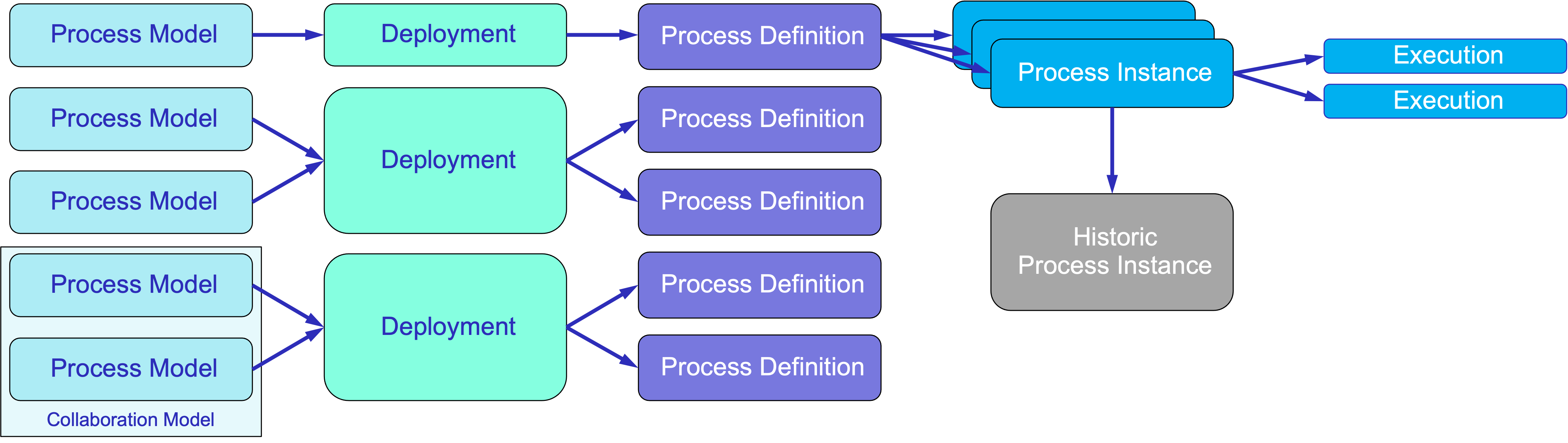
Ниже приведено детальное описание артефактов процесса.
Модель Процесса
Модель процесса представляет собой структурированное представление бизнес-процесса в XML-формате с использованием стандарта BPMN 2.0. Модель состоит из нескольких секций, которые вместе описывают поведение и поток бизнес-процесса.
Секция <definitions> является корневым элементом XML-файла BPMN. Она содержит всю модель процесса и предоставляет контекст для различных компонентов, определенных внутри него. Этот раздел обычно включает метаданные о модели, такие как XML-пространство имен и местоположение схемы, что обеспечивает соответствие документа стандарту BPMN.
Внутри раздела <definitions> вы найдете либо элемент <process>, либо элемент <collaboration>.
-
Элемент
<process>определяет один процесс, связанные с ним действия, события и шлюзы. Это наиболее распространенная структура, используемая при моделировании простого бизнес-процесса. -
Элемент
<collaboration>используется, когда несколько процессов взаимодействуют друг с другом, позволяя строить сложные представления процессов с участием различных участников или сущностей. В этом случае создается модель сотрудничества.
Модель процесса также включает определения событий для сообщений, сигналов и ошибок.
Наконец, раздел <diagram> предоставляет визуальное представление модели процесса, обычно с использованием графической нотации. Этот раздел удобен для составителей процесса и для читателей, так как позволяет им визуализировать поток и структуру процесса. Хотя диаграмма не влияет на выполнение процесса, она улучшает понимание и коммуникацию между заинтересованными сторонами.
Ниже приведен пример визуальной модели процесса в нотации BPMN 2.0 и ее XML-представление:
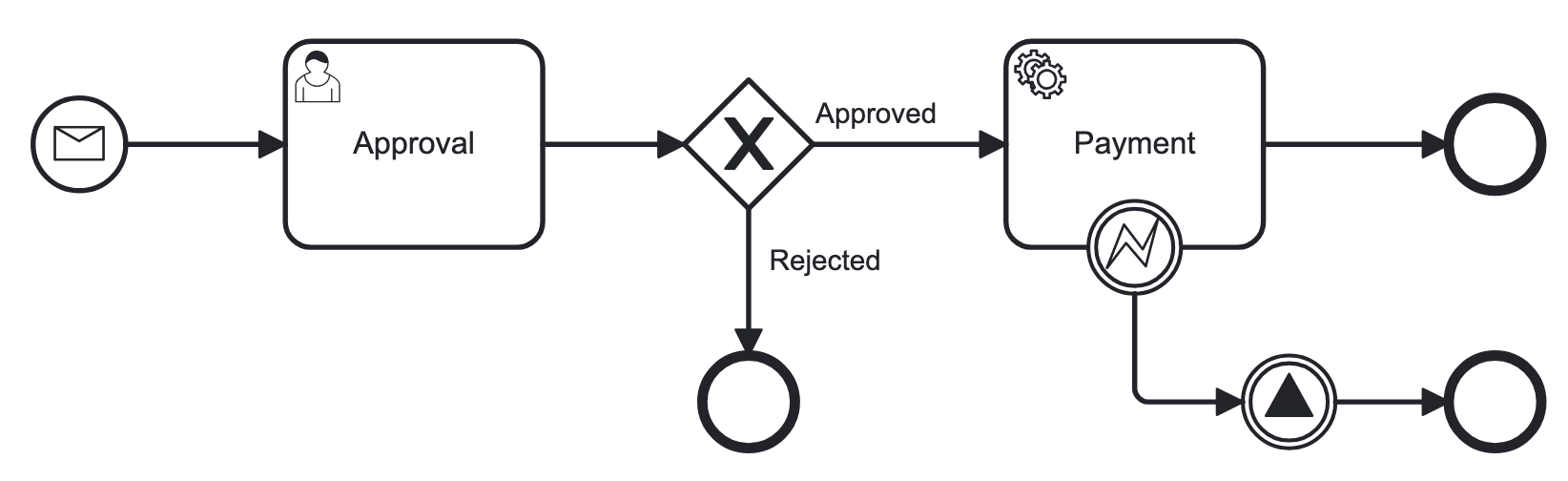
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" <!--Other namespases.... --> >
<!--Process definition-->
<process id="document-approval" name="Document approval" isExecutable="true">
<!--Process elements-->
<process/>
<!--Event definitions-->
<message id="start-approval-process" name="Start approval process" />
<signal id="payment-failed" name="Payment failed" flowable:scope="global" />
<error id="payment-serice-error" name="Payment serice error" errorCode="900" />
<!--Diagram section-->
<bpmndi:BPMNDiagram id="BPMNDiagram_process">
<!-- Diagram elements -->
<bpmndi:BPMNDiagram/>
</definitions>Черновики и Процессы
Модель процесса существует в двух состояниях: черновик и готов к развертыванию. Технически обе версии являются действительными моделями BPMN; основное различие заключается в их местах хранения. А версия черновика имеет дополнительное расширение с меткой “.draft”.
Хранение Моделей Процессов
В Studio модели процессов хранятся в директории src/main/resources/process-drafts для черновиков и в src/main/resources/processes для процессов, готовых к развертыванию.
Вы можете изменить местоположение моделей процессов, используя Flowable Application Properties, но мы рекомендуем использовать стандартные местоположения.
Кроме того, вы можете создавать и хранить черновики во время выполнения, используя экран Моделера в запущенном приложении.
| Черновики созданные в Studio и в веб-приложении содержатся в различных хранилищах. Они не синхронизированы и содержат разные наборы моделей. |
Объект Развертывания
Объект развертывание служит контейнером для различных ресурсов, связанных с бизнес-процессами, таких как модели процессов BPMN, изображения, формы и другие артефакты.
Бизнес Архив
Чтобы развернуть процессы, их необходимо упаковать в бизнес архив (BAR). Бизнес архив является единицей развертывания для процессного движка. Бизнес архив эквивалентен ZIP-файлу. Он может содержать процессы BPMN 2.0, правила DMN и любые другие типы файлов.
Когда бизнес архив развертывается, он сканируется на наличие файлов BPMN с расширением .bpmn20.xml или .bpmn. Каждый из этих файлов будет обработан и может содержать несколько определений процессов. Когда движок DMN активирован, файлы .dmn также анализируются.
| Jmix BPM не использует формы Flowable. |
Создание Объекта Развертывания
В Jmix BPM развертывания могут быть созданы программно или с помощью интуитивного пользовательского интерфейса.
Программно развертывания создаются с помощью интерфейса DeploymentBuilder через RepositoryService. Ресурсы добавляются в развертывание с использованием методов, таких как addClasspathResource, addInputStream или других методов. После того как все ресурсы включены, развертывание завершается методом deploy():
repositoryService.createDeployment()
.name("Мое Развертывание")
.addClasspathResource("processes/my-process.bpmn") (1)
.addString("greeting", "Привет, мир!") (2)
.deploy();| 1 | – Добавление модели процесса BPMN в виде XML-файла. |
| 2 | – Добавление ресурса в виде строки. |
В Studio процессы развертываются автоматически, см. раздел Автоматическое развертывание моделей для получения подробной информации. Либо вы можете развернуть их, используя функцию Hot Deploy в Studio.
На экране Моделера вы можете развернуть процессы вручную.
После завершения развертывания объект развертывания становится доступным для чтения. Его содержимое не может быть изменено после развертывания, что обеспечивает целостность развернутых ресурсов.
При развертывании Flowable анализирует файлы BPMN XML, включенные в развертывание. Для каждого из файлов Flowable создает одно или несколько определений процессов. Каждое определение процесса является внутренним представлением процесса, определенного в BPMN XML.
Доступ к Развернутым Ресурсам
Чтобы получить доступ к развернутым ресурсам во время выполнения:
//List the resources in the deployment:
List<String> resourceNames = repositoryService.getDeploymentResourceNames(deploymentId);
//Retrieve a specific resource:
InputStream resourceStream = repositoryService.getResourceAsStream(deploymentId, "my-resource.txt");Хранение Развертываний
Созданные определения процессов хранятся в базе данных Flowable, в частности, в таблице ACT_RE_DEPLOYMENT.
Удаление Развертываний
Чтобы удалить развертывание в Flowable, вы можете использовать RepositoryService.
// Specify the deployment ID you want to delete
// Replace with your actual deployment ID
String deploymentId = "yourDeploymentId";
// Delete the deployment
// The second parameter indicates whether to cascade delete process instances
repositoryService.deleteDeployment(deploymentId, true);Первый параметр — это ID развертывания, который вы можете получить при создании развертывания или запросив существующие развертывания.
Второй параметр (true или false) определяет, следует ли каскадно удалять все экземпляры процессов, связанные с этим развертыванием. Если установить значение true, все активные и исторические экземпляры процессов, созданные из этого развертывания, также будут удалены.
Если каскадное удаление установлено на false, любые активные или исторические экземпляры процессов, созданные из процессов, определенных в этом развертывании, не будут удалены. Создание новых экземпляров на основе определения станет невозможным, но существующие экземпляры останутся в системе.
| Вы можете вручную удалить определенный объект развертывания на экране Process definition details. Но имейте в виду, что эта операция удалит ВСЕ определения развернутые вместе. |
Свойств Объекта Развертывания
Объект развертывания обладает следующими свойствами:
| Свойство | Описание |
|---|---|
Id |
Уникальный идентификатор развертывания. |
Name |
Имя объекта. |
Deployment Time |
Временная метка, указывающее, когда было произведено развертывание. |
Resources |
Коллекция ресурсов (например, файлы BPMN, таблицы DMN), включенных в объект развертывания. |
Version |
Версия объекта развертывания. |
Определение Процесса
Определение процесса представляет собой шаблон для исполняемого бизнес-процесса. Оно определяет структуру, действия и логику процесса, позволяя процессному движку создавать и выполнять экземпляры процесса на основе определенных моделей процесса.
Создание Определения Процесса
Создать определение процесса напрямую невозможно. Оно будет создано во время развертывания.
Каждое определение процесса связано с конкретным объектом развертывания, которое служит контейнером для одного или нескольких определений процессов и связанных с ними ресурсов.
Увидеть список определений процессов, развернутых в системе, можно на экране Process Definitions.
Приостановка и Активация
Определение процесса имеет два состояния: active и suspended.
-
Active: В этом состоянии определение может использоваться для создания и выполнения процессов на основе его структуры.
-
Suspended: В этом состоянии новые экземпляры не могут быть запущены на основе этого определения, но существующие экземпляры, которые уже выполняются, могут продолжать работу.
Переход между состояниями выполняется следующим образом:
// Suspending a process definition
repositoryService.suspendProcessDefinitionByKey(processDefinitionKey);
// Activating a suspended process definition
repositoryService.activateProcessDefinitionByKey(processDefinitionKey);Также вы можете приостанавливать и активировать определение процесса по ID.
Версионирование Определений Процессов
Во время развертывания процессный движок присваивает версию определению процесса перед его сохранением в базе данных. Таким образом, определения процессов версионируются, что позволяет одновременно существовать нескольким версиям одного и того же процесса.
Свойство id устанавливается в формате
{processDefinitionKey}:{processDefinitionVersion}:{generated-id},
где generated-id – это уникальный номер, который гарантирует, что ID процесса будет уникальным.
Свойство process id из модели процесса копируется в свойство key определения процесса.
|
Доступ к Определениям Процессов
Чтобы получить доступ к определениям процессов во время выполнения:
// Querying for all process definitions in deployment
List<ProcessDefinition> processDefinitions = repositoryService.createProcessDefinitionQuery()
.deploymentId(deploymentId)
.list();
// Querying for all versions of the process definition
repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.list();
// Querying for the latest version of the process definition
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.latestVersion()
.singleResult();Хранение Определений Процессов
Определения процессов хранятся в базе данных в таблице ACT_RE_PROCDEF.
Удаление Определения Процесса
Если вам нужно удалить определение процесса, необходимо также удалить связанный объект развертывания. См. Удаление Развертываний.
Свойства Определения Процесса
Определение процесса в Flowable имеет следующие свойства:
| Свойство | Описание |
|---|---|
ID |
Уникальный идентификатор определения процесса. |
Key |
Ключ, который уникально идентифицирует определение процесса среди версий. (Важно: в модели процесса это свойство называется`process ID`.) |
Name |
Имя определения процесса. |
Version |
Номер версии определения процесса. |
Deployment ID |
Идентификатор объекта развертывания к которому принадлежит данное определение. |
Resource Name |
Имя XML-файла BPMN, который определяет процесс. |
Category |
Пользовательский параметр. |
Экземпляр Процесса
Экземпляр процесса — это запущенный бизнес-процесс, который выполняет конкретное определение процесса и имеет свое собственное состояние и данные.
Жизненный Цикл Экземпляра Процесса
Жизненный цикл экземпляра процесса включает несколько этапов, которые представляют различные состояния и переходы запущенного процесса.
Создание
Создать экземпляр процесса можно с помощью RuntimeService, используя методы startProcessInstanceByKey или startProcessInstanceById.
Администратор BPM может запустить процесс вручную через экран Process Definitions, а пользователи через экран Start Process.
На этом этапе можно передать начальные переменные, которые повлияют на выполнение процесса.
// Example variable for the process
Map<String, Object> variables = new HashMap<>();
variables.put("employeeId", "12345");
ProcessInstance processInstance = runtimeService
.startProcessInstanceByKey("my-process", variables);ProcessInstanceBuilder builder = runtimeService.createProcessInstanceBuilder()
.processDefinitionKey("myProcess")
.businessKey("holidayRequest-123")
.variable("employeeId", "12345")
.start();
ProcessInstance processInstance = builder.start();Активное Состояние
После создания экземпляр процесса переходит в состояние Active, где начинает выполнять задачи, определенные в модели процесса. Экземпляр будет проходить через различные задачи, события и шлюзы, указанные в модели BPMN.
Запрос для проверки, активен ли экземпляр процесса:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.active()
.singleResult();Если экземпляр процесса был приостановлен, вы можете его активировать:
runtimeService.activateProcessInstanceById(processInstanceId);Приостановленное Состояние
Экземпляр процесса может быть переведён в состояние Suspended, что временно останавливает его выполнение без завершения. Это позволяет проводить обслуживание или обновления, не теряя текущее состояние экземпляра. В приостановленном состоянии задачи не будут выполняться, но существующие задачи все еще можно просматривать.
Вы можете приостановить экземпляр процесса на экране Process Instance detail или программно:
runtimeService.suspendProcessInstanceById(processInstanceId);Запрос для проверки, приостановлен ли экземпляр процесса:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.suspended()
.singleResult();Завершение
Экземпляр процесса считается завершенным после выполнения всех задач и событий. Однако специального состояния Complete не существует. Завершенный экземпляр процесса подлежит удалению, и создается соответствующий исторический экземпляр процесса. Эти исторические данные могут быть использованы для отчетности и аудита.
Все переменные, установленные во время выполнения процесса, фиксируются и хранятся в истории, что позволяет их извлечение и анализ после завершения.
После завершения процессный движок может инициировать определенные события, заданные в модели BPMN, такие как конечные события или сигналы, которые могут запустить дальнейшие действия или уведомления в системе.
Доступ к Экземплярам Процесса
Чтобы получить список экземпляров во время исполнения:
// Querying for all instances of a specific process definition
List<ProcessInstance> instances = runtimeService.createProcessInstanceQuery()
.processDefinitionKey(key)
.list();Чтобы получить конкертный экземпляр по его id:
// Querying for a specific process instance by ID
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(instanceId)
.singleResult();Хранение Экземпляров Процессов
Процессный движок хранит экземпляры процессов в таблице с названием ACT_RU_EXECUTION.
Удаление Экземпляра Процесса
Для удаления экземпляра процесса:
runtimeService.deleteProcessInstance(processInstanceId, "Delete reason");Свойства Экземпляра Процесса
| Свойство | Описание |
|---|---|
Process Instance ID |
Уникальный идентификатор. |
Business Key |
Необязательный бизнес-ключ для идентификации экземпляра. |
Parent ID |
Если значение поля null, то данное выполнение представляет собой экземпляр процесса. Если значение присутствует, то оно является ID родителя этого выполнения. |
Process Definition ID |
ID определения процесса, на основе которого создан экземпляр. |
Start Time |
Временная метка, когда был запущен экземпляр процесса. |
End Time |
Временная метка, когда экземпляр процесса был завершен (если применимо). |
Duration |
Продолжительность выполнения экземпляра процесса. |
State |
Продолжительность выполнения экземпляра процесса (например, running, suspended, completed). |
Variables |
Переменные, связанные с экземпляром процесса. |
Объект выполнения (Execution)
Если экземпляр процесса содержит несколько потоков выполнения (как, например, после прохождения параллельного шлюза), то внутри экземпляра процесса будут созданы несколько объектов выполнения по одному для каждого параллельного пути выполнения. Выполнения также создаются для областей, например при достижении встроенного подпроцесса или многократных активностей (multi-instance activities) в бизнес процессе. Сам по себе экземпляр также является корневым выполнением которые может иметь дочерние выполнения, представляющие подпроцессы или параллельные действия.
|
Метод getParentId() позволяет получить ID родительского выполнения, устанавливая четкую связь между родительскими и дочерними выполнениями, что важно для управления сложными рабочими процессами.
Дочерние выполнения могут содержать локальные переменные, специфичные для их контекста.
Доступ к Выполнениям
Чтобы получить список выполнений конкретного экземпляра процесса:
List<Execution> childExecutions = runtimeService.createExecutionQuery()
.processInstanceId(processInstanceId)
.list();Удаление объекта выполнения
Выполнения связаны с родительским экземпляром процесса. Вы не можете удалить отдельное выполнение, если оно является частью активного экземпляра процесса, не удаляя весь экземпляр.
| Убедитесь, что выполнение, которое вы собираетесь удалить, не активно и не находится в состоянии, которое может помешать удалению. Если есть параллельные транзакции или зависимости, могут возникнуть исключения. |
Свойства Выполнения
Выполнение имеют тот же набор свойств, что и экземпляр процесса. См. Свойства Экземпляра Процесса.
Экземпляр Задачи
Экземпляр задачи представляет собой конкретное выполнение задачи в рамках процесса. Когда выполнение процесса достигает пользовательской задачи, сервисной задачи или любой другой задачи, создается её экземпляр. Экземпляры задач используются для отслеживания и управления выполнением задач пользователями или системами.
Независимая Задача
Независимые задачи не связаны напрямую с конкретным экземпляром процесса. Такая возможность предоставляет дополнительную гибкость для управления задачами в различных сценариях. Например:
Task newTask = taskService.newTask();
newTask.setName("Standalone Task");
newTask.setAssignee("userId"); // Assign to a user
taskService.saveTask(newTask);Доступ к Экземплярам Задач
Экземпляры задач можно получить программно:
//Getting task by ID
Task task = taskService.createTaskQuery().taskId(taskId).singleResult();
//Getting a list of tasks, assigned to user
List<Task> tasks = taskService.createTaskQuery().taskAssignee("userId").list();Хранение Экземпляров Задач
Активные экземпляры задач хранятся в базе данных, в частности, в таблицах ACT_RU_TASK. Каждый экземпляр задачи связан с соответствующим экземпляром процесса и контекстом выполнения.
Удаление Экземпляра Задачи
Экземпляр задачи можно удалить программно:
taskService.deleteTask(taskId, "Reason for deletion");| Удаление задачи может существенно повлиять на связанный экземпляр процесса. |
Свойства экземпляра задачи
| Свойство | Описание |
|---|---|
Id |
Уникальный идентификатор экземпляра задачи. |
Execution Id |
Идентификатор выполнения, связанного с задачей. |
Process Instance Id |
Идентификатор экземпляра процесса, к которому принадлежит задача. |
Process Definition Id |
Идентификатор определения процесса, связанного с задачей. |
Task Definition Id |
Идентификатор определения задачи, на основе которой создан этот экземпляр. |
State |
Текущая стадия задачи (например, created, assigned, completed). |
Name |
Название задачи, как определено в модели BPMN. |
Description |
Описание, предоставляющее дополнительные детали о задаче. |
Task Definition Key |
Ключ, используемый для ссылки на определение задачи в запросах. (Соответствует параметру 'task id' в модели процесса.) |
Owner |
Идентификатор пользователя, который владеет задачей. |
Assignee |
Идентификатор пользователя, которому в настоящее время назначена задача. |
Delegation |
Идентификатор для любой делегации, связанной с этой задачей. |
Priority |
Уровень приоритета, назначенный этой задаче, влияющий на порядок ее обработки. |
Create Time |
Время создания задачи. |
In Progress Time |
Время, когда работа над задачей началась. |
In Progress Started By |
Идентификатор пользователя, который начал работу над этой задачей. |
Claim Time |
Время, когда задачу принял пользователь. |
Claimed By |
Идентификатор пользователя, который принял эту задачу. |
Suspended Time |
Время, когда задача была приостановлена, если применимо. |
Suspended By |
Идентификатор пользователя, который приостановил эту задачу. |
In Progress Due Date |
Срок выполнения работы над этой задачей, пока она в процессе. |
Due Date |
Окончательный срок, к которому задача должна быть завершена. |
Category |
Категория или тип задачи. |
Suspension State |
Состояние, указывающее, приостановлена ли задача или активна. |
Переменные Процесса
В BPMN переменные процесса представляют данные, используемые во время выполнения экземпляра процесса. Они служат контейнерами для информации, которая может влиять на поток процесса, хранить промежуточные результаты или предоставлять входные данные для задач и действий.
Переменные могут использоваться в выражениях, например, для выбора правильного исходящего последовательного потока в эксклюзивном шлюзе. В сервисных задачах они могут использоваться при вызове внешних сервисов, например, для предоставления входных данных или хранения результата вызова сервиса и так далее.
Сохранение Переменных Процесса
В отличие от переменных Java, переменные процесса являются сущностями, управляемыми движком процесса. Движок создает экземпляры переменных процесса, когда процесс запускается или когда определяются и инициализируются новые переменные.
Таким образом, они по сути являются контейнерами, хранящими значения известных типов Java.
Типы переменных процесса
В Jmix BPM поддерживаемые типы переменных:
-
String
-
Multiline string
-
Decimal
-
Number
-
Boolean
-
Date
-
Date with time
-
Entity
-
Entity list
-
File
-
Platform enum
-
Object (не доступен для использования в процессных формах)
Тип Entity подразумевает сущности Jmix определенные в модели данных. Для хранения переменных в базе данных используется формат вида <entity-name>."<UUID>"". Например: jbt_User."60885987-1b61-4247-94c7-dff348347f93".
При использовании переменных типа Entity List учтите, что размер списка имеет ограничение в 4000 символов. Если предположить, что для элемента требуется 50 символов, то в списке будет 80 элементов. Если лимит превышен, это вызовет исключение при сохранении.
Однако, можно использовать переменные и большего размера в пределах транзакционных границ, когда сохранение в базу данных не требуется. Также, можно использовать transient переменные.
Области видимости переменных
Переменные процесса имеют определенную область видимости, обычно связанную с экземпляром процесса. Это означает, что они доступны на протяжении выполнения этого экземпляра, но могут быть недоступны за его пределами. Таким образом, любая задача, подпроцесс или событие в рамках одного и того же экземпляра процесса могут читать и записывать эти переменные.
Local Variables
Local variables in BPMN are variables that exist within a specific scope, typically tied to a particular task or subprocess. Within multi-instance activities, local variables can be defined for each instance. They are used to store data that is relevant only within that scope and are not accessible outside it.
Transient Переменные
Transient переменные ведут себя как обычные переменные, но имеют ограниченное время жизни – они не хранятся в базе данных и не хранятся в истории. Обычно временные переменные используются для сложных сценариев. Если вы не уверены, используйте обычную переменную процесса.
Использование переменных процесса
Вы можете передавать переменные в экземпляр процесса при его запуске:
ProcessInstance startProcessInstanceByKey(String processDefinitionKey, Map<String, Object> variables);Переменные можно добавлять во время выполнения процесса. Например:
void setVariable(String executionId, String variableName, Object value);
void setVariableLocal(String executionId, String variableName, Object value);
void setVariables(String executionId, Map<String, ? extends Object> variables);
void setVariablesLocal(String executionId, Map<String, ? extends Object> variables);Переменные также можно получать методами приведёнными ниже:
Map<String, Object> getVariables(String executionId);
Map<String, Object> getVariablesLocal(String executionId);
Map<String, Object> getVariables(String executionId, Collection<String> variableNames);
Map<String, Object> getVariablesLocal(String executionId, Collection<String> variableNames);
Object getVariable(String executionId, String variableName);
<T> T getVariable(String executionId, String variableName, Class<T> variableClass);Переменные часто используются в делегатах Java, выражениях, слушателях выполнения, слушателях задач, скриптах и так далее. В этих конструкциях доступны текущие объекты выполнения или задачи, и их можно использовать для установки и/или извлечения переменных. Самые простые методы следующие:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);Свойства переменных процесса
| Свойство | Описание |
|---|---|
ID |
Уникальный идентификатор переменной процесса. |
Type |
Определяет тип данных, который может содержать переменная, например, строка, целое число, логическое значение и т.д. |
Name |
Название переменной. |
Execution ID |
Ссылается на выполнение, в рамках которого определена переменная процесса. |
Process instance ID |
Ссылается на экземпляр процесса, в рамках которого определена переменная процесса. |
Task instance ID |
Ссылается на экземпляр задачи, в рамках которого определена переменная процесса. |